| CPC G10L 15/197 (2013.01) [G10L 13/00 (2013.01); G10L 15/005 (2013.01); G10L 15/08 (2013.01); G10L 15/14 (2013.01); G10L 15/1822 (2013.01); G10L 15/22 (2013.01); G10L 15/30 (2013.01); G10L 2015/088 (2013.01); G10L 2015/223 (2013.01); G10L 2015/228 (2013.01)] | 6 Claims |
|
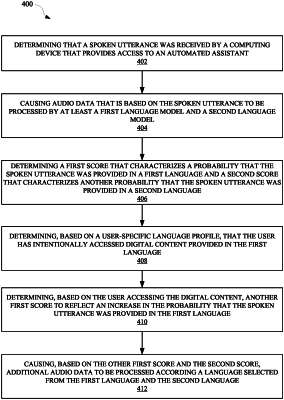
1. A method implemented by one or more processors, the method comprising:
determining that a spoken utterance was received by a computing device from a user, the computing device comprising an automated assistant that is capable of being invoked in response to the user providing the spoken utterance;
causing audio data, which is based on the spoken utterance, to be processed, by at least a first language model and a second language model, wherein the first language model and the second language model are selected according to a user-specific preference of language models for interpreting spoken utterances from the user;
determining, based on processing of the audio data, a first score that characterizes a probability that the spoken utterance was provided in a first language and a second score that characterizes another probability that the spoken utterance was provided in the second language;
determining, based on a user-specific language profile that is accessible to the automated assistant, that the user has intentionally accessed digital content provided in the first language;
determining, based on determining that the user has intentionally accessed the digital content provided in the first language, another first score to reflect an increase in the probability that the spoken utterance was provided in the first language; and
causing, based on the other first score and the second score, additional audio data to be processed according to a language selected from at least the first language and the second language.
|