| CPC G10L 15/187 (2013.01) [G06N 20/00 (2019.01); G10L 15/02 (2013.01); G10L 15/063 (2013.01); G10L 15/22 (2013.01); G10L 2015/025 (2013.01)] | 20 Claims |
|
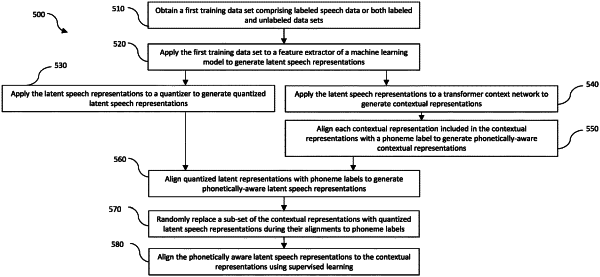
1. A computing system comprising:
one or more processors; and
one or more computer-readable instructions that are executable by the one or more processors to configure the computing system to at least:
obtain a first training data set comprising labeled speech data or both labeled and unlabeled data sets;
apply the first training data set to a feature extractor of a machine learning model to generate latent speech representations;
apply the latent speech representations to a quantizer to generate quantized latent speech representations;
apply the latent speech representations to a transformer context network to generate contextual representations;
align each contextual representation included in the contextual representations with a phoneme label to generate phonetically aware contextual representations;
align quantized latent representations with phoneme labels to generate phonetically aware latent speech representations;
randomly replace a sub-set of the contextual representations with quantized latent speech representations during their alignments to phoneme labels; and
align the phonetically aware latent speech representations to the contextual representations using supervised learning.
|