| US 11,735,156 B1 | ||
| Synthetic speech processing | ||
| Jaime Lorenzo Trueba, Cambridge (GB); Alejandro Ricardo Mottini d'Oliveira, Seattle, WA (US); Thomas Renaud Drugman, Carnieres (BE); and Sri Vishnu Kumar Karlapati, Cambridge (GB) | ||
| Assigned to Amazon Technologies, Inc., Seattle, WA (US) | ||
| Filed by Amazon Technologies, Inc., Seattle, WA (US) | ||
| Filed on Aug. 31, 2020, as Appl. No. 17/007,709. | ||
| Int. Cl. G10L 13/02 (2013.01); G10L 15/08 (2006.01); G06F 3/16 (2006.01); G06N 3/084 (2023.01); G10L 25/30 (2013.01) | ||
| CPC G10L 13/02 (2013.01) [G06F 3/16 (2013.01); G06N 3/084 (2013.01); G10L 15/08 (2013.01); G10L 25/30 (2013.01); G10L 2015/088 (2013.01)] | 20 Claims |
|
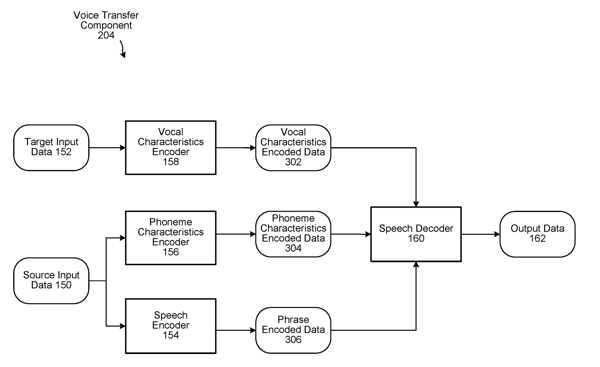
3. A computer-implemented method comprising:
receiving, from at least one microphone of a user device, first audio data representing first noise and first speech corresponding to a first voice, the first speech including a first plurality of words; receiving second audio data corresponding to a second voice different from the first voice; processing, using a first encoder, the first audio data to determine first encoded data corresponding to phoneme characteristics of the first speech; processing, using a second encoder, the first audio data to determine second encoded data corresponding to the first noise and to a phrase of the first speech; processing, using a third encoder, the second audio data to determine third encoded data corresponding to vocal characteristics of the second voice; and processing, using a decoder, the first encoded data, the second encoded data, and the third encoded data to determine third audio data representing second speech corresponding to the second voice, the second speech including the first plurality of words. |