| US 11,734,511 B1 | ||
| Mapping data set(s) to canonical phrases using natural language processing model(s) | ||
| Nanzhu Wang, San Jose, CA (US); Gaoxiang Chen, Mountain View, CA (US); and Yueqi Li, San Jose, CA (US) | ||
| Assigned to MINERAL EARTH SCIENCES LLC, Mountain View, CA (US) | ||
| Filed by Mineral Earth Sciences LLC, Mountain View, CA (US) | ||
| Filed on Jul. 8, 2020, as Appl. No. 16/946,840. | ||
| Int. Cl. G06F 40/289 (2020.01); G06N 3/044 (2023.01) | ||
| CPC G06F 40/289 (2020.01) [G06N 3/044 (2023.01)] | 14 Claims |
|
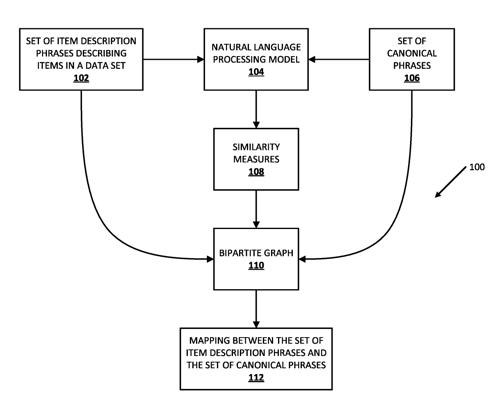
1. A method implemented by one or more processors, the method comprising:
with a Bidirectional Encoder Representation of Transformers (“BERT”) natural language processing (“NLP”) model, processing (a) a set of canonical phrases and (b) a set of item description phrases in an agricultural data set, where each item in the agricultural data set is described by an item description phrase in the set of item description phrases,
wherein the processing generates a similarity measure between each item description phrase in the set of item description phrases, and each canonical phrase in the set of canonical phrases;
generating a bipartite graph based on (a) the set of item description phrases, (b) the set of canonical phrases, and (c) the similarity measure between each item description phrase and each canonical phrase; generating a mapping between the set of canonical phrases and the set of item description phrases based on the bipartite graph,
wherein the mapping between each item description phrase and the corresponding canonical phrase is based on comparing the edge value, of each edge between the corresponding item description vertex and each of the canonical phrase vertices, and
wherein the mapping between each item description phrase and the corresponding canonical phrase is automatically generated to combine the agricultural data set with an additional agricultural data set;
with the BERT NLP model, processing (a) the set of canonical phrases and (b) a set additional of additional item description phrases in the additional agricultural data set, where each item in the additional agricultural data set is described by an additional item description phrase in the set of additional item description phrases, to generate an additional similarity measure between each additional item description phrase in the set of item description phrases, and each canonical phrase in the set of canonical phrases; generating an additional bipartite graph based on (a) the set of additional item description phrases, (b) the set of canonical phrases, and (c) the additional similarity measure between each item description phrase and each canonical phrase; generating an additional mapping from the set of canonical phrases to the set of additional item description phrases based on the additional bipartite graph,
wherein the mapping between each item description phrase and the corresponding canonical phrase is automatically generated to combine the agricultural data set with the additional agricultural data set;
generating a unified agricultural data set based on (a) the set of canonical phrases, (b) the mapping corresponding to the agricultural data set, and (c) the additional mapping corresponding to the additional agricultural data set; training a crop yield model based on the agricultural data set, the additional agricultural data set, the mapping, and the additional mapping; and generating a predicted crop yield for a crop captured in the agricultural data set and/or the additional agricultural data set based on processing the unified agricultural data set using the trained crop yield prediction model. |