| CPC G06F 16/2456 (2019.01) [G06F 16/219 (2019.01); G06F 16/27 (2019.01); G06F 16/285 (2019.01)] | 20 Claims |
|
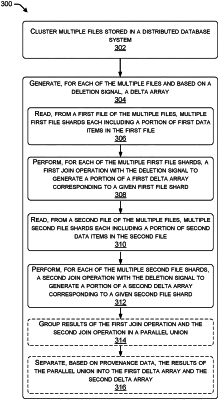
1. A computer-implemented method for performing a vectorized delete in a distributed database system, comprising:
clustering multiple files stored in the distributed database system, wherein the clustering is based at least in part on a similarity in a storage scheme used to store data in the multiple files; and
generating, for each of the multiple files and based on a deletion signal, a delta array including multiple bits representing data items in the file and indicating, based on bit value, target data items to be deleted from the file, wherein generating, for each of the multiple files, the delta array includes:
reading, from a first file of the multiple files, multiple first file shards each including a portion of first data items in the first file;
performing, for each of the multiple first file shards, a first join operation with the deletion signal to generate a portion of a first delta array corresponding to a given first file shard;
reading, from a second file of the multiple files, multiple second file shards each including a portion of second data items in the second file; and
performing, for each of the multiple second file shards, a second join operation with the deletion signal to generate a portion of a second delta array corresponding to a given second file shard,
wherein reading at least one second file shard of the multiple second file shards is performed before the first join operation on at least one first file shard of the multiple first file shards is completed.
|