| CPC B25J 9/1661 (2013.01) [B25J 9/161 (2013.01); B25J 13/003 (2013.01); G06T 7/20 (2013.01); G06V 20/00 (2022.01); G06V 40/107 (2022.01); G06V 40/28 (2022.01); G06T 2207/10024 (2013.01); G06T 2207/10028 (2013.01); G06T 2207/30196 (2013.01)] | 19 Claims |
|
1. A computer-implemented method for teaching a robot a task in a cluttered environment, comprising:
receiving an input;
parsing the input to identify a task and a target object name;
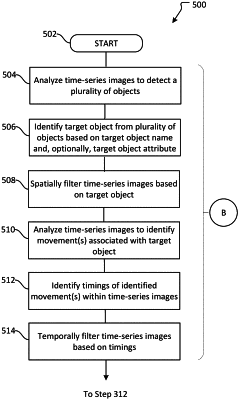
receiving a set of time-series images;
detecting a plurality of objects within the set of time-series images, wherein the set of time-series images depicts a demonstration of the task associated with a target object;
based on the target object name, identifying the target object among the plurality of objects within the set of time-series images;
generating a spatially filtered set of time-series images by spatially filtering the set of time-series images based on the target object;
identifying a timing of at least one physical human movement for performing the task associated with the target object within the spatially filtered set of time-series images;
generating a spatio-temporal filtered set of time-series images by temporally filtering the spatially filtered set of time-series images based on the timing of the at least one physical human movement; and
evaluating the spatio-temporal filtered set of time-series images to isolate one or more skill parameters associated with performing the task.
|