| CPC G06F 18/2185 (2023.01) [G06N 3/086 (2013.01)] | 18 Claims |
|
1. A system for controlling a plurality of autonomous platforms, the system comprising:
one or more processors and a non-transitory computer-readable medium having executable instructions encoded thereon such that when executed, the one or more processors perform operations of:
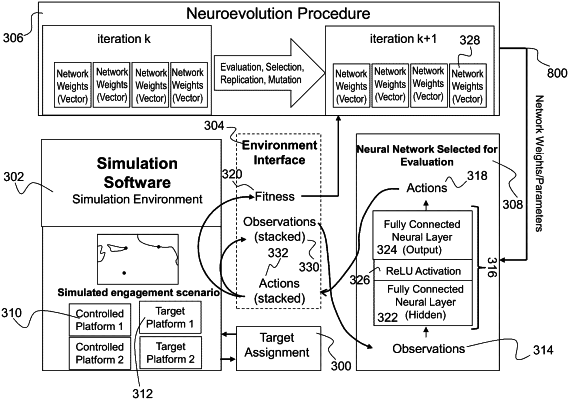
performing a training process to produce a trained learning agent in a simulation environment comprising a plurality of controlled platforms and a plurality of target platforms, comprising:
for each simulation time-step until an episode ends:
assigning each controlled platform to one target platform, wherein each target platform produces an observation;
processing, with a learning agent, each observation using a deep learning network;
for each observation, producing, by the learning agent, an action corresponding to each controlled platform until an action has been produced for each controlled platform in the simulation environment;
obtaining a reward value corresponding to the episode; and
executing the trained learning agent to control each autonomous platform comprising a plurality of platform sensors and platform actuators, wherein executing the trained agent comprises:
receiving, by the trained agent, one or more observations from at least one platform sensor;
producing a behavior-level action based on the one or more observations; and
causing one or more platform actuators to perform a physical action based on the behavior-level action.
|