| CPC H04W 74/0875 (2013.01) [G06N 3/045 (2023.01); H04L 5/003 (2013.01); H04W 74/002 (2013.01)] | 8 Claims |
|
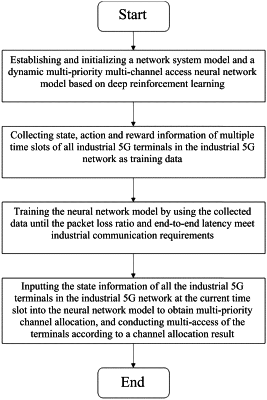
1. An industrial 5G dynamic multi-priority multi-access method based on deep reinforcement learning, comprising the following steps:
1) establishing a dynamic multi-priority multi-channel access neural network model based on deep reinforcement learning;
2) collecting state, action and reward information of T time slots of all industrial 5G terminals in the industrial 5G network as training data to train the neural network model; and
3) collecting the state information of all the industrial 5G terminals in the industrial 5G network at the current time slot as the input of the neural network model; conducting multi-priority channel allocation through the neural network model; and conducting multi-access by the industrial 5G terminals according to a channel allocation result,
wherein step 1 further comprises:
constructing two neural network models with the same structure of q-eval deep neural network and q-next deep neural network, and neural network parameters params=[xin, xmn, xfc, xout, w, b],
wherein xin represents the number of neurons on an input layer and is equal to the length of a state vector sn of the industrial 5G terminal n (n∈N), N represents the number of the industrial 5G terminals, xmn represents the number of neurons on a recurrent neural network layer, xfc represents the number of neurons on a fully connected layer, xout represents the number of neurons on an output layer and is equal to the length of an action vector an of the industrial 5G terminal n, w represents a weight, and b represents an offset,
wherein the q-eval deep neural network is used for obtaining a valuation function Q(sn,an) of the action vector an of the current state vector sn of the industrial 5G terminal n, the q-next neural network model is used for selecting the valuation function maxa′nQ(s′n, a′n of the maximum action vector a′n of the next state vector s′n of the industrial 5G terminal n;
updating the q-eval deep neural network parameters w and b using reinforcement learning Q(sn, an)=Q(sn, an)+α(rn+γ maxa′nQ(s′n, a′n)−Q(sn, an)), wherein α represents a learning rate; γ represents a discount ratio, and rn represents a reward obtained by the industrial 5G terminal n in the current state sn by executing the action vector an,
the initialization parameters of the q-next deep neural network being the same as the initialization parameters of the q-eval deep neural network; updating the parameters w and b of the q-eval deep neural network after each iterative training of the neural network model, and updating the parameters w and b of the q-next deep neural network once after each iterative training of the neural network model for I times.
|