| CPC H04L 63/1425 (2013.01) [G06N 3/088 (2013.01); G06N 20/00 (2019.01)] | 20 Claims |
|
1. A computer-implemented method comprising:
receiving data associated with performances of microservices functioning in a distributed computing environment;
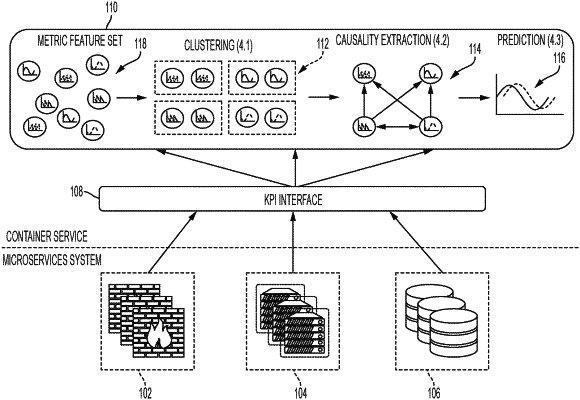
clustering the data into clusters of types of metrics by executing an unsupervised machine learning algorithm;
selecting a representative data from a cluster, the representative data being representative of time series data in the cluster, the selecting performed for a plurality of the clusters wherein the representative data is selected for each of the plurality of the clusters;
based on time series data of the representative data associated with the plurality of the clusters, performing a causal extraction, the causal extraction inferring dependencies among a plurality of different time series data wherein a time series data in the plurality of different time series data represents metrics of a microservice, the causal extraction recognizing cause-effect relationships between different metrics among the microservices;
constructing a causal graph based on at least the cause-effect relationships between the different metrics among microservices, the causal graph having nodes and edges connecting at least some of the nodes, wherein each node of the causal graph represents a microservice's metric type;
embedding the causal graph into vector space, wherein the nodes of the causal graph embedded into the vector space are concatenated with time series data associated with respective nodes, wherein the embedding the causal graph into vector space incorporates spatial components of the causal graph and temporal components of the microservices' metrics, wherein an embedding for a given node of the nodes is represented as a position in a k-dimensional array, wherein k depends on a number of reference nodes selected in the causal graph as co-ordinates for assigning distances, wherein a dimension of the k-dimensional array is computed as a total number of hops away from a pre-selected node, the pre-selected node being one of the reference nodes; and
based on the embedded vector space used as a feature vector that represents a fusion of graph embedding with time series data, training an artificial neural network model for managing the distributed computing environment, wherein the representative data selected for each of the plurality of the clusters is used for managing the distributed computing environment.
|