| CPC G10L 25/30 (2013.01) [G06N 3/08 (2013.01); G10L 25/78 (2013.01); G10L 2025/783 (2013.01)] | 6 Claims |
|
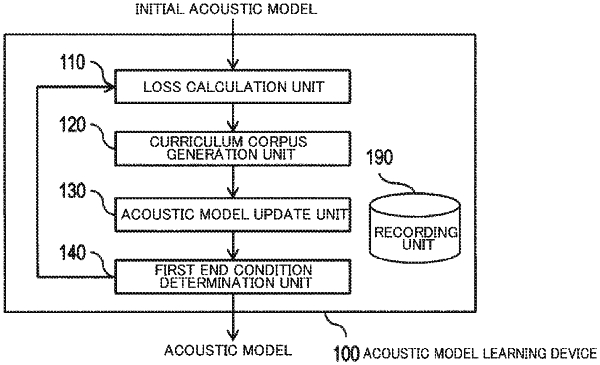
1. An acoustic model learning device, comprising:
a loss generator configured to determine, for a corpus Cj (j=1, . . . , J) for learning, a loss of sound data which is an element of the corpus Cj (j=1, . . . , J) for learning by using an acoustic model θ, where J represents an integer equal to or larger than one and the corpus Cj (j=1, . . . , J) for learning represents a set of sound data;
a curriculum corpus generator configured to generate a curriculum corpus C being a union of subsets of the corpuses Cj (j=1, . . . , J) for learning, the corpuses Cj (j=1, . . . , J) including, as elements, sound data for which the loss falls within a predetermined range indicating a small value;
the curriculum corpus generator configured to update sound data used for generating the curriculum corpus C so that the number of times η sound data has been selected as an element of the curriculum corpus C is updated by incrementing by one;
an acoustic model updater configured to update the acoustic model θ by using the curriculum corpus C; and a first end condition determination unit configured to output the acoustic model θ when a predetermined end condition is satisfied, or transfer execution control to the loss generator when the predetermined end condition is not satisfied, wherein the acoustic model updater is configured to update the acoustic model θ by giving a weight to a gradient for sound data which is an element of the curriculum corpus C using such a weight w for sound data as to have a smaller value as a number of times n the sound data has been selected as an element of the curriculum corpus becomes larger.
|