| CPC G10L 19/02 (2013.01) [G10H 1/366 (2013.01); G10L 19/00 (2013.01); G10L 21/055 (2013.01); G10H 2210/051 (2013.01); G10H 2240/141 (2013.01); G10H 2250/235 (2013.01)] | 20 Claims |
|
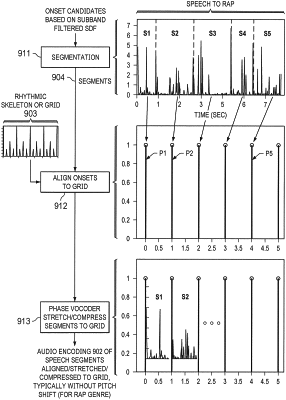
1. A computational method for transforming an input audio encoding of speech into an output that is rhythmically consistent with a target song, the method comprising:
temporally aligning successive, time-ordered ones of plural segments of the input audio encoding with respective successive pulses of a rhythmic skeleton for the target song;
temporally stretching or compressing at least some of the temporally aligned segments to substantially fill available temporal space between respective ones of the successive pulses of the rhythmic skeleton, wherein the temporal stretching or compressing is performed at rates that vary for respective ones of the temporally aligned segments in accord with respective ratios of segment length to temporal space to be filled;
padding with silence at least one segment of the temporally aligned segments to substantially fill available temporal space of the at least one segment; and
preparing a resultant audio encoding of the speech in correspondence with the temporally aligned, stretched or compressed segments of the input audio encoding.
|