| CPC G10L 17/24 (2013.01) [G10L 15/26 (2013.01); G10L 17/06 (2013.01); G10L 21/028 (2013.01)] | 20 Claims |
|
1. A method implemented by one or more processors, the method comprising:
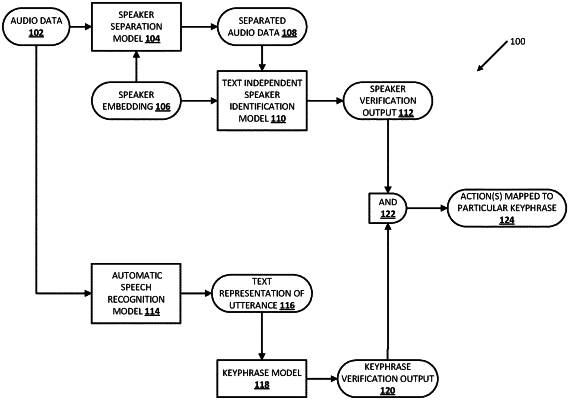
receiving audio data that captures an utterance of a human speaker and that also captures one or more additional sounds that are not from the human speaker;
processing the audio data and a pre-generated speaker embedding that corresponds to the human speaker, using a speaker separation model, to generate separated audio data which separates the utterance of the human speaker from the one or more additional sounds that are not from the human speaker;
processing the separated audio data using a text independent speaker verification model to generate speaker verification output;
determining, based on comparing the speaker verification output to the pre-generated speaker embedding that corresponds to the human speaker, that the human speaker spoke the utterance;
processing, the audio data or the separated audio data, using an automatic speech recognition (“ASR”) model to generate a text representation of the utterance; and
in response to determining that the human speaker spoke the utterance:
causing a client device to perform one or more actions that are based on the text representation.
|