| CPC G10L 15/1815 (2013.01) [G06N 3/08 (2013.01); G10L 15/063 (2013.01); G10L 15/16 (2013.01); G10L 15/22 (2013.01); G10L 15/28 (2013.01); G10L 2015/228 (2013.01)] | 20 Claims |
|
1. A computer-implemented method comprising:
receiving a first audio frame corresponding to a first portion of first audio data representing a first spoken input;
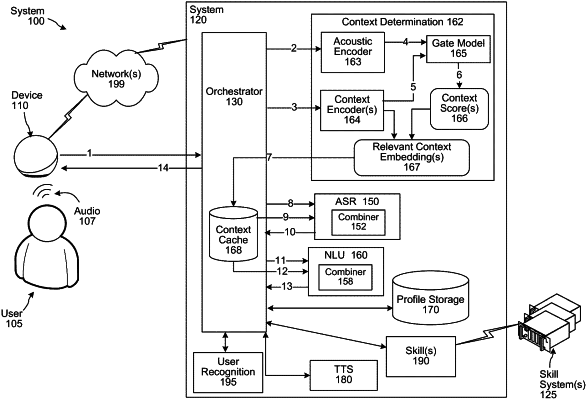
determining, using an acoustic encoder, first audio embedding data corresponding to the first audio frame;
receiving first context data representing device information;
receiving second context data representing dialog turn information;
determining, using a first context encoder configured to process device context data, first context embedding data corresponding to the first context data;
determining, using a second context encoder configured to process dialog turn context data, second context embedding data corresponding to the second context data;
determining, using a first trained machine learning (ML) model, a first context score representing a similarity between the first audio embedding data and the first context embedding data;
determining, using the first trained ML model, a second context score representing a similarity between the first audio embedding data and the second context embedding data;
identifying, in a context storage, a third context score corresponding to third context data based on processing a second audio frame received prior to the first audio frame, the second audio frame corresponding to a second portion of the first audio data;
storing, based at least in part on processing the first context score and the second context score with respect to the third context score, the first context embedding data and the first context score in the context storage;
processing, using an attention component, the first audio embedding data and at least the first context embedding data to determine combined embedding data;
processing, using one or more neural networks, at least the combined embedding data to determine intent data and entity data corresponding to the first spoken input; and
determining, using the intent data and the entity data, a first output responsive to the first spoken input.
|