| CPC G10L 15/063 (2013.01) [G10L 15/16 (2013.01); G10L 15/183 (2013.01); G10L 15/28 (2013.01)] | 15 Claims |
|
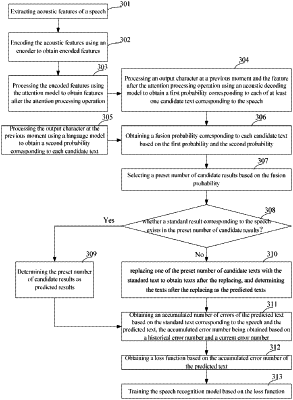
1. A method for training a speech recognition model, the speech recognition model comprising an acoustic decoding model and a language model, the method comprising:
obtaining a fusion probability of each of at least one candidate text corresponding to a speech based on the acoustic decoding model and the language model;
selecting a preset number of one or more candidate texts based on the fusion probability of each of the at least one candidate text, and determining a predicted text based on the preset number of one or more candidate texts; and
obtaining a loss function based on the predicted text and a standard text corresponding to the speech, and training the speech recognition model based on the loss function,
wherein the obtaining the loss function based on the predicted text and the standard text corresponding to the speech comprises:
obtaining an accumulated number of errors of the predicted text based on the predicted text and the standard text corresponding to the speech, the accumulated error number being obtained based on a historical error number and a current error number; and
obtaining the loss function based on the accumulated error number of the predicted text.
|