| CPC G10L 13/00 (2013.01) [A63F 13/60 (2014.09); G06N 3/044 (2023.01); G06N 3/08 (2013.01); A63F 13/63 (2014.09); A63F 2300/6018 (2013.01)] | 20 Claims |
|
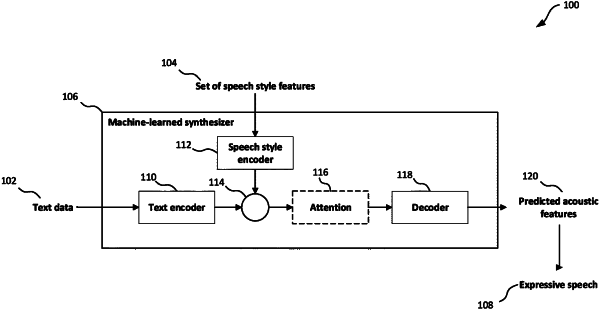
1. A system for use in video game development for generating expressive speech audio, the system comprising:
a user interface configured to receive user-input text data and a user selection of a speech style; and
a machine-learned synthesizer comprising a text encoder, a speech style encoder and a decoder, the machine-learned synthesizer being configured to:
generate one or more text encodings derived from the user-input text data, using the text encoder of the machine-learned synthesizer;
generate a speech style encoding by processing a set of speech style features associated with the selected speech style using the speech style encoder of the machine-learned synthesizer;
combine the one or more text encodings and the speech style encoding to generate one or more combined encodings; and
decode the one or more combined encodings with the decoder of the machine-learned synthesizer to generate predicted spectrogram parameters for the expressive speech audio.
|