| CPC G06T 7/55 (2017.01) [B60R 1/00 (2013.01); B60W 60/001 (2020.02); G05D 1/0212 (2013.01); G05D 1/0246 (2013.01); G05D 1/248 (2024.01); G05D 1/646 (2024.01); G06F 18/214 (2023.01); G06F 18/2148 (2023.01); G06N 3/08 (2013.01); G06T 3/04 (2024.01); G06T 3/18 (2024.01); G06T 3/40 (2013.01); G06T 7/11 (2017.01); G06T 7/292 (2017.01); G06T 7/579 (2017.01); H04N 23/90 (2023.01); B60R 2300/102 (2013.01); B60W 2420/403 (2013.01); G06T 2207/10028 (2013.01); G06T 2207/20081 (2013.01); G06T 2207/20084 (2013.01); G06T 2207/30244 (2013.01); G06T 2207/30252 (2013.01)] | 18 Claims |
|
1. A method for scale-aware depth estimation using multi-camera projection loss, comprising:
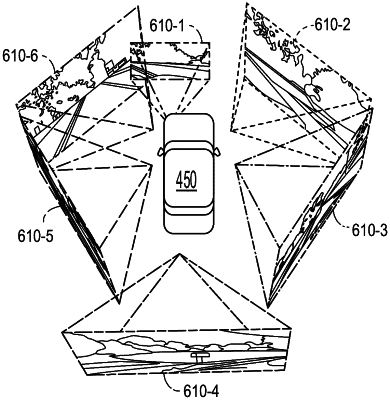
determining a multi-camera photometric loss associated with a 360° multi-camera rig of an ego vehicle having a reduced overlap region between images captured by cameras of the 360° multi-camera rig less than thirty degrees;
training a scale-aware depth estimation model and an ego-motion estimation model according to the multi-camera photometric loss by leveraging cross-camera temporal contexts via spatio-temporal photometric constraints to increase an amount of overlap between images captured by the cameras of the 360° multi-camera rig using the ego-motion estimation of the ego vehicle;
generating increased overlap images from the images captured by each camera of the 360° multi-camera rig of the ego vehicle using a trained scale-aware depth estimation model and a trained ego-motion estimation model;
generating a full surround mono-depth (FSM) 360° point cloud from reduced the increased overlap images to illustrate a scene surrounding the ego vehicle according to a scale-aware depth and an ego-motion estimation using the trained scale-aware depth estimation model and the trained ego-motion estimation model; and
planning a vehicle control action of the ego vehicle according to the FSM 360° point cloud of the scene surrounding the ego vehicle.
|