| CPC G06T 13/205 (2013.01) [G06T 13/40 (2013.01); G06T 17/20 (2013.01)] | 20 Claims |
|
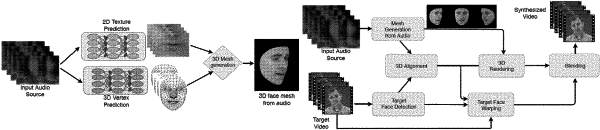
1. A computing system to generate a talking face from an audio signal, the computing system comprising:
one or more processors; and
one or more non-transitory computer-readable media that collectively store:
a machine-learned face geometry prediction model configured to predict a face geometry based on data descriptive of an audio signal that comprises speech;
a machine learned face texture prediction model configured to predict a face texture based on data descriptive of the audio signal that comprises the speech; and
instructions that, when executed by the one or more processors, cause the computing system to perform operations, the operations comprising:
obtaining the data descriptive of the audio signal that comprises speech;
using the machine-learned face geometry prediction model to predict the face geometry based at least in part on the data descriptive of the audio signal;
using the machine-learned face texture prediction model to predict the face texture based at least in part on the data descriptive of the audio signal; and
combining the face geometry with the face texture to generate a three-dimensional face mesh model.
|