| CPC G06T 13/205 (2013.01) [G06F 3/011 (2013.01); G06F 3/017 (2013.01); G06Q 50/01 (2013.01); G10L 15/183 (2013.01); G10L 15/26 (2013.01); G10L 21/10 (2013.01); H04M 11/10 (2013.01)] | 20 Claims |
|
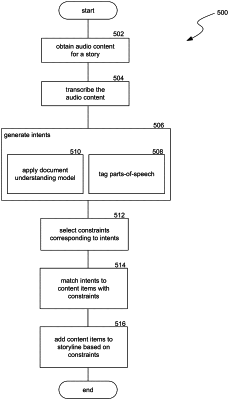
1. A method for automatically generating a visual story from audio content using a computing system to automatically perform each method step, the method comprising:
A) obtaining audio content comprising a natural language segment containing a plurality of spoken words;
B) transcribing, by a transcriber element of the computing system, the natural language segment into text;
C) generating, by an intent generator element of the computing system, an intent specifying a relationship between a part of the text and a topic specified in the text,
wherein the intent is generated by:
applying a document understanding model to the text to obtain the topic; and
applying a parts-of-speech model to the text to obtain at least one grammatical relationship,
wherein the computing system stores i) a list of existing story universes; each existing story universe corresponding to a movie or a television program, and ii) multiple content items specified for respective ones of the existing story universes, each content item being mapped to the corresponding movie or television program, and
wherein the story takes place within one of the existing story universes on the list and includes a plurality of scenes at respective different times within the story;
D) selecting, by a constraint applier element of the computing system, 1) a universe constraint identifying one of the existing story universes on the list, and 2) a constraint that matches a characteristic of the intent;
E) matching, by the constraint applier element and based on the constraint, the intent to one or more content items, of the multiple content items specified for respective ones of the existing story universes,
wherein each of the matched one or more content items is constrained by the constraint applier element, based on the universe constraint, to be one of the content items specified for the movie or television program corresponding to the identified existing story universe;
F) generating, by a storyline builder element of the computing system, a scene taking place by using the matched one or more content items to create visual output; and
G) repeating steps A) to F) at least once, as additional audio content, comprising additional natural language segments, are received.
|