| CPC G06T 1/20 (2013.01) [G06F 5/01 (2013.01); G06F 7/501 (2013.01); G06F 7/523 (2013.01); G06F 7/5443 (2013.01); G06F 17/153 (2013.01); G06F 17/16 (2013.01); G06N 3/044 (2023.01); G06N 3/045 (2023.01); G06N 3/063 (2013.01); G06N 3/084 (2013.01); G06F 2207/382 (2013.01); G06F 2207/4824 (2013.01)] | 20 Claims |
|
1. A graphics processing unit comprising:
an interface coupled to an interconnect fabric; and
a graphics core cluster including a plurality of multiprocessors that are interconnected via a data interconnect, a multiprocessor of the plurality of multiprocessors including circuitry configured to:
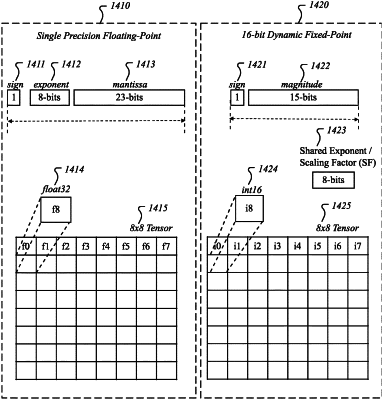
convert elements of a floating-point tensor into elements of a fixed-point tensor, wherein to convert an element of the floating-point tensor, the circuitry is to compute a right-shift value based on a run-time configurable scale factor associated with the floating-point tensor and right-shift a mantissa of the element based on the right-shift value to generate a magnitude integer;
perform a compute operation on input including data elements of the fixed-point tensor; and
generate an output tensor via the compute operation.
|