| CPC G06N 3/063 (2013.01) [G06N 3/044 (2023.01); G06N 3/045 (2023.01); G06N 3/084 (2013.01)] | 20 Claims |
|
1. An apparatus comprising:
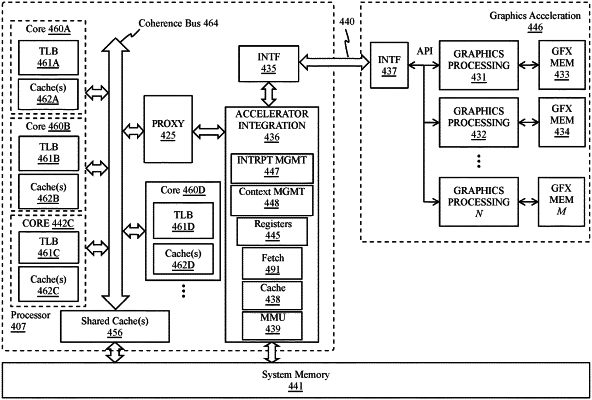
a cluster of distinct interconnected graphics processors, each graphics processor including a plurality of processing resources; and
processing circuitry to schedule operations to the cluster of distinct interconnected graphics processors, the processing circuitry configured to:
determine a traversal strategy for a deep learning neural network, the traversal strategy to be implemented via dispatch components of the graphics processors in the cluster of distinct interconnected graphics processors; and
convey the traversal strategy to the dispatch components of the graphics processors, the graphics processors configured to:
receive the traversal strategy and data for the deep learning neural network;
traverse a solution space of the deep learning neural network to score a plurality of solutions to schedule deep learning network execution on the plurality of processing resources of a graphics processor of the cluster of distinct interconnected graphics processors;
select a solution from the plurality of solutions to implement the deep learning network based on scores associated with the plurality of solutions; and
implement a workload schedule to assign tasks to the plurality of processing resources, wherein the workload schedule specifies a batch of grouped operations, the operations of the batch of grouped operations determined via a machine learning model based on historical data associated with the cluster of distinct interconnected graphics processors.
|