| CPC G06F 40/211 (2020.01) [G06F 40/253 (2020.01); G06F 40/284 (2020.01); G06F 40/40 (2020.01); G06N 20/00 (2019.01)] | 14 Claims |
|
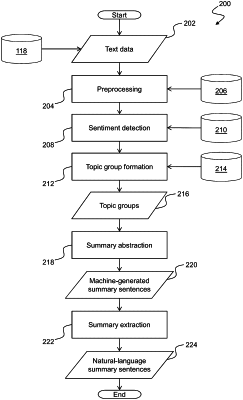
1. A computer-implemented method for summarising text, comprising:
identifying, based on a search query, a plurality of text documents;
obtaining a plurality of input sentences defining the text documents, the input sentences comprising respective sets of tokens;
forming a plurality of topic groups comprising respective subsets of the input sentences according to a predetermined mapping between the tokens and topic identifiers;
executing a natural language processing module employing a language model trained using tagged samples of text in a target language, to determine, for each token of the input sentences, part-of-speech (POS) data representing a grammatical function of the token in its corresponding input sentence;
substituting each token with a token/POS pair based on the POS data determined via execution of the model;
for each topic group:
(i) constructing a graph data structure having a plurality of nodes representing unique token/POS pairs, and edges connecting the nodes in sequences corresponding to the input sentences of the corresponding topic group,
(ii) generating a plurality of ranked candidate summary sentences based upon subgraphs of the graph data structure having initial and final nodes representing valid sentence start and end token/POS pairs, and
(iii) selecting the top-ranked candidate summary sentence;
(iv) computing a numerical suitability measure for each input sentence in the topic group based on comparisons between the top-ranked candidate summary sentence, and the input sentences, and
(v) selecting, as a natural-language summary for the topic group, a preferred one of the input sentences, based on the numerical suitability measures; and
returning, in response to the search query, a summary of the plurality of text documents comprising the natural-language summary for each topic group.
|