| CPC G06F 21/32 (2013.01) [B60W 40/08 (2013.01); G06V 10/762 (2022.01); G06V 10/774 (2022.01); G06V 10/82 (2022.01); G06V 20/59 (2022.01); G06V 40/172 (2022.01); B60W 2040/0809 (2013.01); B60W 2540/043 (2020.02); B60W 2540/215 (2020.02)] | 13 Claims |
|
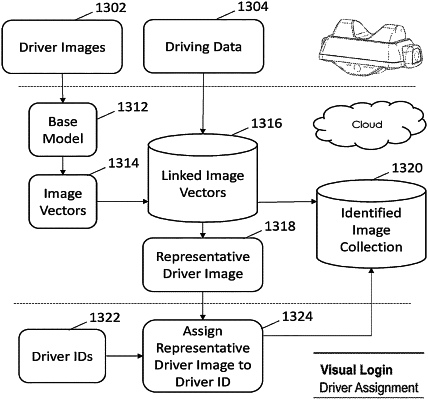
1. A method for preparing training data for a visual login system, comprising:
receiving, by at least one processor of a computing device, one or more driver identifiers, wherein each driver identifier corresponds to a driver who is associated with a vehicle fleet;
receiving, by the at least one processor, a first plurality of driver images of a first driver, wherein each driver image of the first plurality of driver images was captured by a camera mounted to a vehicle, wherein the vehicle is in the vehicle fleet;
clustering, by the at least one processor and based on an embedding space projection, the first plurality of driver images of the first driver to produce at least one image cluster, wherein a first image cluster of the at least one image cluster corresponds to a gaze direction of the driver while driving the vehicle, and wherein the gaze direction further corresponds to the driver looking in the direction of the camera;
selecting, by the at least one processor, a representative image from the first image cluster;
displaying, by the at least one processor and to a user:
the representative image of the first driver from the first plurality of driver images; and
the one or more driver identifiers;
receiving, by the at least one processor, input data from the user, wherein the input data indicates a selected driver identifier from the one or more driver identifiers;
associating, by the at least one processor, the selected driver identifier with every driver image of the first plurality of driver images of the first driver including the representative image; and
training, by the at least one processor, a fleet-specific model based on the first plurality of driver images and the associated driver identifier, wherein the fleet-specific model is trained based on an input of an image vector of the representative image and the selected driver identifier, and wherein the fleet-specific model is trained to compare a candidate image to a plurality of image vectors to select a highest probability driver identifier.
|