| CPC G06F 17/153 (2013.01) [G06F 12/0875 (2013.01); G06N 3/04 (2013.01); G06N 3/063 (2013.01); G06F 2212/1024 (2013.01)] | 18 Claims |
|
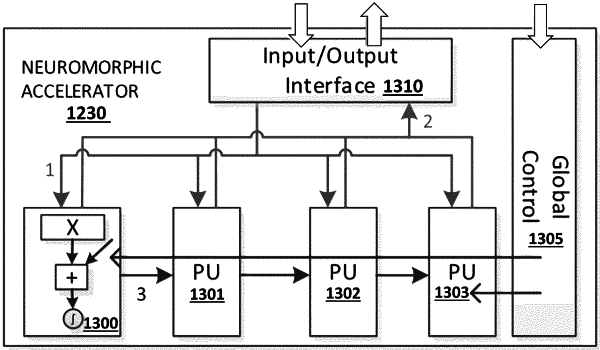
1. An apparatus to perform artificial neural network (ANN) processing comprising:
an input/output (I/O) interface;
a plurality of processing circuits communicatively coupled to the I/O interface to receive data for input neurons and synaptic weights associated with each of the input neurons, each of the plurality of processing circuits to process at least a portion of the data for the input neurons and the synaptic weights to generate partial results, wherein the plurality of processing circuits includes at least four processing circuits;
an interconnect communicatively coupling the plurality of processing circuits, each of the processing circuits to share the partial results with one or more other of the plurality of processing circuits over the interconnect, the one or more other of the processing circuits to use the partial results to generate additional partial results or final results; and
a plurality of latches to store the received data for the input neurons and the synaptic weights associated with each of the input neurons, wherein the received data for a given computation is to be broadcast to all other of the plurality of processing circuits by providing the latched received data to said all other of the plurality of processing circuits over a plurality of processing cycles to avoid reading the received data from the I/O interface multiple times during the given computation.
|