| CPC G06F 16/3322 (2019.01) [G06F 16/3334 (2019.01); G06F 40/284 (2020.01); G06N 20/00 (2019.01)] | 20 Claims |
|
1. In a digital medium environment, a method implemented by a computing device, the method comprising:
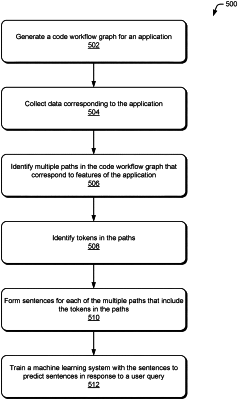
generating a code workflow graph for an application, the code workflow graph including multiple nodes each corresponding to a different function or method in the application and having an associated tag that is a name of the function or method, connections between nodes indicating functions or methods in the application that invoke other functions or methods in the application;
identifying multiple paths in the code workflow graph that correspond to features of the application, each of the multiple paths including two or more nodes of the multiple nodes that are connected in the code workflow graph;
pruning, from the multiple paths, one or more paths between a first node and a second node of the code workflow graph that are not a shortest path between the first node and the second node, and at least one path having a path weightage that is less than a threshold, the path weightage indicating how many other paths of the multiple paths include the at least one path, the pruned paths being removed from the code workflow graph resulting in a pruned code workflow graph;
identifying tokens in paths of the pruned code workflow graph, the tokens comprising terms included in the tags associated with the nodes in the paths, the identified tokens excluding the tokens that represent the terms in the tags that occur most frequently in the code workflow graph;
forming, for each of the paths of the pruned code workflow graph, a sentence that includes the identified tokens in the path in an order in which the tokens occur in the path; and
using the sentences formed from the multiple paths as training data to train a machine learning system to predict which ones of the sentences formed from the paths of the pruned code workflow graph correspond to a user query received as input by the trained machine learning system.
|