| CPC G06F 16/258 (2019.01) [G06F 16/285 (2019.01); G06F 18/2413 (2023.01)] | 20 Claims |
|
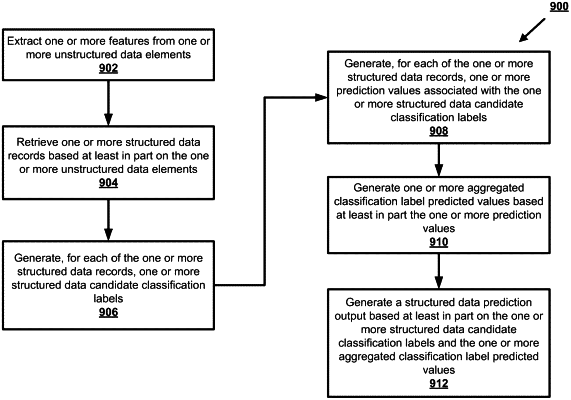
1. A computer-implemented method for performing data standardization on unstructured data, the computer-implemented method comprising:
for each of one or more unstructured data elements of classification input data, generating, by a computing entity and using a natural language processing (NLP) machine learning model, an NLP candidate classification label;
for each of the one or more unstructured data elements, generating, by the computing entity and using a structured data classification machine learning model, a structured data candidate classification label associated with the unstructured data element based at least in part on structured data;
classifying, by the computing entity and using a common data classification machine learning model, each of the one or more unstructured data elements based at least in part on each NLP candidate classification label and each structured data candidate classification label, wherein classifying each of the one or more unstructured data elements comprises:
(a) determining a distance measure difference between a top-ranking synonymous word associated with the unstructured data element and a next top-ranking synonymous word associated with the unstructured data element,
(b) assigning a selected NLP candidate classification label to the unstructured data element based at least in part on the distance measure difference being above a threshold, and
(c) using, based at least in part on the distance measure difference being below the threshold, an ensemble machine learning model to:
(i) determine a top-ranking structured data candidate classification label matching a top-ranking NLP candidate classification label associated with the top-ranking synonymous word, and
(ii) for each instance of the top-ranking structured data candidate classification label that does not match the top-ranking NLP candidate classification label, generate an aggregate probability score based at least in part on the NLP candidate classification label and the structured data candidate classification label; and
initiating, by the computing entity, the performance of one or more prediction-based actions based at least in part on the classification of the one or more unstructured data elements.
|