| CPC B25J 9/1669 (2013.01) [B25J 9/162 (2013.01); B25J 9/1666 (2013.01); B25J 9/1697 (2013.01)] | 12 Claims |
|
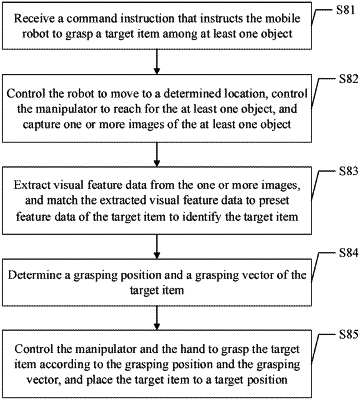
1. A computer-implemented vision-guided picking and placing method for a mobile robot that comprises a manipulator having a hand and a camera, the method comprising:
receiving a command instruction that instructs the mobile robot to grasp a target item among at least one object;
controlling the mobile robot to move to a determined location associated with the at least one object, controlling the manipulator to reach for the at least one object, and capturing one or more images of the at least one object using the camera in real time;
extracting visual feature data from the one or more images, matching the extracted visual feature data to preset feature data of the target item in a database to identify the target item, and determining a grasping position and a grasping vector of the target item, wherein the grasping position is determined based on a type of the hand of the manipulator and is higher than a center of gravity of the target item, and the grasping vector comprises a grasping pose; and
controlling the manipulator and the hand to grasp the target item according to the grasping position and the grasping vector, and placing the target item to a target position;
wherein. before receiving the command instruction, the method further comprises:
scanning at least one sample item associated with a pick-and-place task performed by the mobile robot to obtain template images corresponding to each of the at least one sample item, wherein the at least one sample item comprises the target item, and the template images are captured at a plurality of different perspectives around each sample item;
inserting grasping data of at least one pair of grasping points into each template image, wherein the grasping data comprises a grasping position and a grasping vector associated with the at least one sample item, and the at least one pair of grasping points are positions on each sample item in contact with fingers of the hand such that each sample item can be grasped by the hand; and
storing the template images and the grasping data corresponding to the template images as feature data of a corresponding one of the at least one sample item;
wherein extracting visual feature data from the one or more images and matching the extracted visual feature data to preset feature data of the target item in the database to identify the target item comprises:
extracting a plurality of the visual feature data from each frame of the one or more images using an oriented fast and rotated brief (ORB) algorithm; and
matching the plurality of the visual feature data to the visual feature data of the target item using a balanced binary search method and a nearest Euclidean distance algorithm to identify the target item, wherein the visual feature data of the target item is extracted from a template image of the target item by using the ORB algorithm; and
wherein determining the grasping position and the grasping vector of the target item comprises:
when the manipulator is reaching for the target item, capturing a plurality of images of the target item using the camera:
according to the grasping position and the grasping vector inserted in the template images, determining a first promising area of each of the plurality of the images of the target item;
controlling the manipulator to move closer to the first promising area, and determining a second promising area of the first promising area of each of the plurality of the images of the target item by performing a plurality of detections in the first promising area, wherein each detection finds best grasping positions and best grasping vector for the first promising area, and the hand is controlled to approach the target item according to the best grasping positions and best grasping vector after each detection; and
controlling the hand to move toward the target item according to a determining result until the manipulator grasps the target item, wherein the determining result refers to detected grasping positions and grasping vector when a distance between the hand and the target item is less than a preset distance.
|