| CPC H04L 41/0866 (2013.01) [H04L 41/0654 (2013.01); H04L 41/082 (2013.01); H04L 41/0806 (2013.01); H04L 41/0895 (2022.05); H04L 41/5054 (2013.01); H04L 43/08 (2013.01); H04L 43/20 (2022.05)] | 24 Claims |
|
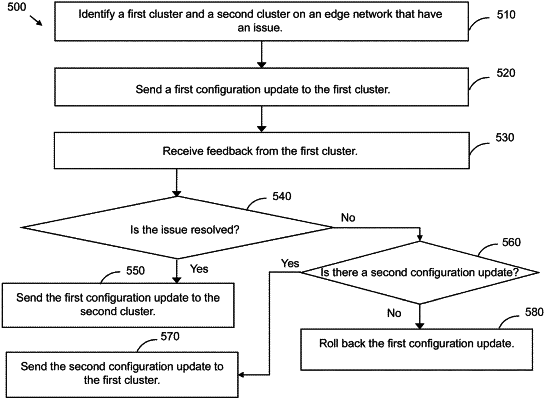
1. An apparatus comprising a processor and a memory, wherein the memory comprises instructions that, when executed by the processor, cause the apparatus to:
collect, at a cloud server, service data from multiple clusters, via a collector framework service of an edge network;
correlate the service data across the multiple clusters of the edge network;
identify a cluster health threshold for the multiple clusters;
predict an issue in at least one cluster of the edge network, wherein the issue is predicted to cause a health of the at least one cluster to be below the cluster health threshold; and
provide an updated configuration to the at least one cluster, via the collector framework service based on the service data.
|