| CPC G11B 27/036 (2013.01) [G06N 3/08 (2013.01); G06T 3/0093 (2013.01); G06T 5/002 (2013.01); G06T 5/005 (2013.01); G06V 10/82 (2022.01); G06V 20/44 (2022.01); G06V 40/161 (2022.01); G06T 2207/10016 (2013.01); G06T 2207/10024 (2013.01); G06T 2207/20081 (2013.01); G06T 2207/20084 (2013.01); G06T 2207/30201 (2013.01)] | 20 Claims |
|
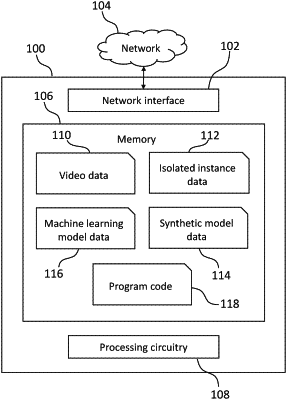
1. A system comprising at least one processor and at least one memory comprising instructions which, when executed by the at least one processor, cause the at least one processor to carry out operations comprising:
identifying instances of an object within video data comprising a plurality of image frames;
for at least some of the identified instances of the object:
determining portions of image frames containing the instance of the object;
determining, for each of the image frames containing the instance of the object, corresponding parameter values for a synthetic model of the object; and
training a deep neural network, the training comprising:
for each determined portion of an image frame containing the instance of the object:
rendering a synthetic image of the instance of the object using the synthetic model and the corresponding parameter values for the synthetic model; and
generating a composite image comprising at least part of the rendered synthetic image and part of the determined portion of the image frame; and
adversarially training the deep neural network to reconstruct the determined portions of the image frames based on the generated composite images.
|