| CPC G10L 21/0208 (2013.01) [G06F 3/167 (2013.01); G06F 17/142 (2013.01); G06N 3/02 (2013.01); G10L 15/063 (2013.01); G10L 15/065 (2013.01); G10L 15/20 (2013.01); G10L 15/22 (2013.01); G10L 2015/223 (2013.01); G10L 2021/02082 (2013.01); G10L 2021/02166 (2013.01)] | 16 Claims |
|
1. A method implemented by one or more processors, comprising:
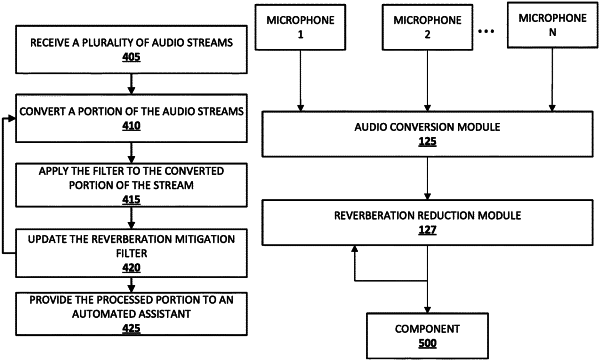
receiving a plurality of audio signal streams, wherein each of the audio signal streams is based on output from a corresponding one of a plurality of microphones of a client device;
at each of a plurality of iterations during a spoken utterance of a user that is detected at the plurality of microphones and that influences the audio signal streams:
converting most recent unprocessed portions of the audio signal streams into corresponding frequency domain representations;
updating a multi-microphone adaptive reverberation filter utilizing the corresponding frequency domain representations of the audio signal streams for at least one prior iteration of the plurality of iterations, wherein, at a given iteration, updating the multi-microphone adaptive reverberation filter utilizing the corresponding frequency domain representations of the audio signal streams for at least one prior iteration of the plurality of iterations comprises:
updating the multi-microphone adaptive reverberation filter utilizing the corresponding frequency domain representations of the audio signal streams for a prior iteration that is at least N iterations prior to the given iteration, and wherein N is greater than one;
utilizing the updated multi-microphone adaptive reverberation filter in generating reverberation mitigated versions of the corresponding frequency domain representations for the most recent unprocessed portions of the audio signal streams; and
providing the reverberation mitigated versions of the corresponding frequency domain representations for further processing by at least one additional component.
|
|
9. A client device, comprising:
a plurality of microphones; and
one or more processors configured to:
receiving a plurality of audio signal streams, wherein each of the audio signal streams is based on output from a corresponding one of the plurality of microphones;
at each of a plurality of iterations during a spoken utterance of a user that is detected at the plurality of microphones and that influences the audio signal streams:
convert most recent unprocessed portions of the audio signal streams into corresponding frequency domain representations;
update a multi-microphone adaptive reverberation filter utilizing the corresponding frequency domain representations of the audio signal streams for at least one prior iteration of the plurality of iterations, wherein, at a given iteration, in updating the multi-microphone adaptive reverberation filter utilizing the corresponding frequency domain representations of the audio signal streams for at least one prior iteration of the plurality of iterations, one or more of the processors are to:
update the multi-microphone adaptive reverberation filter utilizing the corresponding frequency domain representations of the audio signal streams for a prior iteration that is at least N iterations prior to the given iteration, and wherein N is greater than one;
utilize the updated multi-microphone adaptive reverberation filter in generating reverberation mitigated versions of the corresponding frequency domain representations for the most recent unprocessed portions of the audio signal streams; and
provide the reverberation mitigated versions of the corresponding frequency domain representations for further processing by at least one additional component.
|