| CPC G10L 15/22 (2013.01) [G10L 15/1815 (2013.01); G10L 15/30 (2013.01); G10L 2015/223 (2013.01)] | 20 Claims |
|
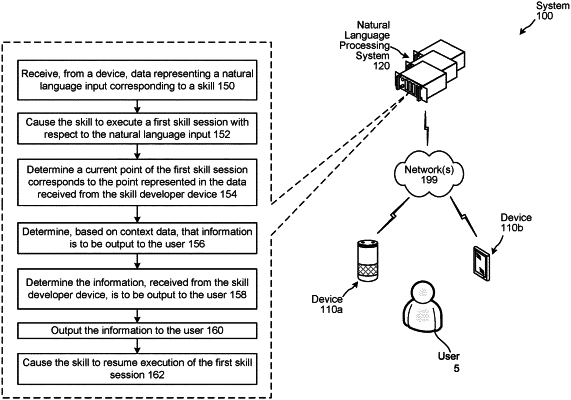
1. A computer-implemented method comprising:
determining first data corresponding to timing for presentation of information during an exchange with a natural language processing system;
receiving, from a first device and after determining the first data, second data representing a first natural language input;
determining a first application is to execute with respect to the first natural language input;
sending, to the first application, third data representing the first natural language input;
processing at least the first data and dialog data using a first component to determine a first indication that an ongoing first dialog corresponding to the first natural language input has reached a first point corresponding to the presentation of information;
determining first information to be output at the first point; and
causing, based at least in part on receiving the first indication, the first device to output the first information.
|