| CPC G10L 15/063 (2013.01) [G06F 9/451 (2018.02); G06F 9/547 (2013.01); G06F 16/2237 (2019.01); G06F 16/248 (2019.01); G06F 16/328 (2019.01); G06F 16/3323 (2019.01); G06F 16/3329 (2019.01); G06F 16/3338 (2019.01); G06F 16/3344 (2019.01); G06F 16/3347 (2019.01); G06F 16/345 (2019.01); G06F 16/367 (2019.01); G06F 16/90332 (2019.01); G06F 40/20 (2020.01); G06F 40/289 (2020.01); G06F 40/30 (2020.01); G06F 40/40 (2020.01); G06N 3/04 (2013.01); G06N 20/00 (2019.01); G10L 15/16 (2013.01); G10L 15/197 (2013.01); G16H 10/60 (2018.01); G16H 40/20 (2018.01); G16H 70/20 (2018.01)] | 20 Claims |
|
1. A computer-implemented method of using domain-specific ontologies of providing summaries of documents in a corpora of natural-language text documents, the method comprising:
obtaining, with a computer system, a set of user-specific context parameters and a natural-language text document;
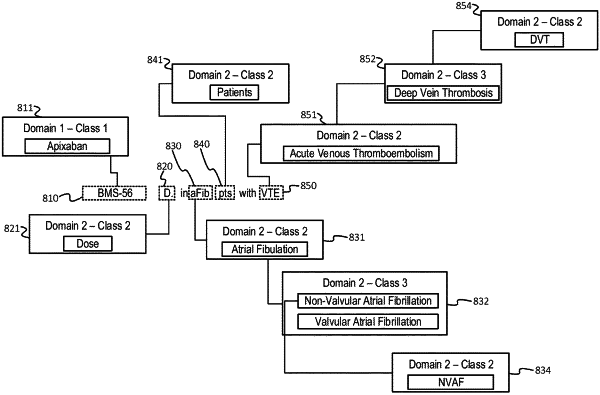
determining, with the computer system, a first domain of knowledge based on the set of user-specific context parameters, wherein the first domain of knowledge maps to a first ontology amongst a plurality of ontologies, and wherein ontologies in the plurality of ontologies map n-grams onto a set of concepts to which the n-grams refer;
scoring, with the computer system, a first set of n-grams of the natural-language text document using a scoring model based on relations between members of the first set of n-grams;
selecting, with the computer system, text sections of the natural-language text based on n-gram scores provided by the scoring model;
determining, with the computer system, an initial set of n-grams of the n-grams, wherein each respective n-gram of the initial set of n-grams maps to a respective concept of the set of concepts, and wherein each respective n-gram is identified by an ontology other than the first ontology;
determining, with the computer system, a set of related n-grams mapped to the set of concepts associated with the first domain of knowledge; and
generating, with the computer system, a text summary for the natural-language text document based on the text sections and the set of related n-grams;
presenting a user interface (UI) to a client computer device, the UI comprising a set of UI elements that, when interacted with, causes the client computer device to send a feedback message;
receiving the feedback message based on an interaction with the set of UI elements;
adjusting a second weight associated with a second ontology associated with a second domain of knowledge, wherein the first ontology is associated with a first weight; and
selecting the second ontology amongst the plurality of ontologies based on the second weight being greater than the first weight.
|