| CPC G06F 40/166 (2020.01) [G06F 40/20 (2020.01); G06F 40/40 (2020.01); G06N 5/022 (2013.01)] | 17 Claims |
|
1. A method for training a multi-document summarization model, comprising:
receiving, via a communication interface, a plurality of documents and a reference summary associated with the plurality of documents;
generating embeddings of sentences from the plurality of documents, wherein the embeddings indicate a relationship between the sentences across the plurality of documents;
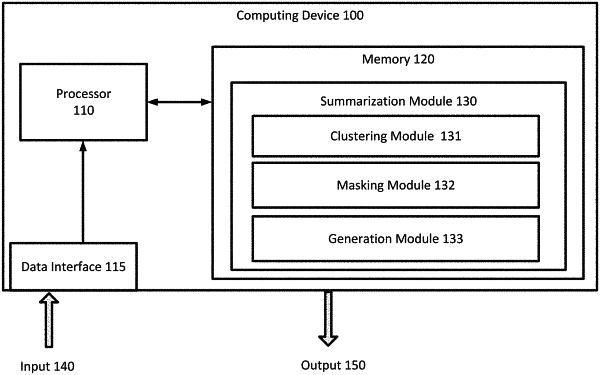
clustering, based on the embeddings, the sentences from the plurality of documents into a plurality of clusters;
aligning one or more reference sentences in the reference summary with the plurality of clusters into a plurality of aligned reference sentence clusters, respectively;
masking a first sentence from one of the plurality of documents based on a determination that the first sentence is contradicted by a second sentence of the plurality of documents
generating, by a natural language processing model without using the first sentence based on the masking, a plurality of cluster-wise summaries corresponding to the plurality of clusters, respectively;
comparing the plurality of cluster-wise summaries and the plurality of aligned reference sentence clusters to compute a loss; and
updating the natural language processing model based on the loss.
|