| CPC G06F 16/74 (2019.01) [G06F 16/40 (2019.01); G06F 16/78 (2019.01)] | 20 Claims |
|
1. A method, comprising:
receiving a digital media capture of a live media content from a user, the digital media capture being submitted by the user on a source device, the source device being communicatively coupled with a display medium, the source device operating to generate a visual display and a user interface on the display medium;
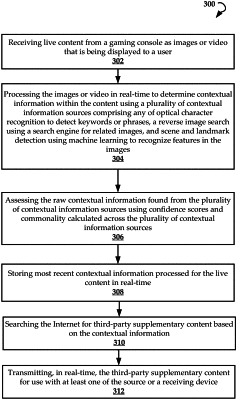
processing the digital media capture to determine contextual information within the live media content, the processing comprising analyzing the digital media capture to extract the contextual information from the live media content by:
timestamping a series of frames of the digital media capture;
performing a reverse image search of the timestamped series of frames using a search engine;
performing one or more of a scene detection, a discrete feature detection, and landmark detection of the timestamped series of frames, said detections using machine learning;
applying a weighting to results of each of the reverse image search and results of performed said detections, the weighting based on a predetermined value assigned to a type of contextual evaluation process;
generating a batch of contextual information over a timeframe; and
performing a first assessment, the first assessment being of contextual information of the batch of contextual information for relevancy using an aggregate of confidence scores and commonality calculated across a plurality of contextual information sources, the aggregate of confidence scores comprising a first confidence score based on frequency of groups of textual data detected by optical character recognition, a second confidence score associated with images identified based on the reverse image search, and a third confidence score associated with one or more features recognized in the digital media capture based on the machine learning;
performing a search of at least one network for supplementary content based on the contextual information of the batch of contextual information extracted from the digital media capture, the search using a search input, the search input being determined by the first assessment;
transmitting the supplementary content to the source device; and
generating, by the source device, an updated visual display, the updated visual display comprising the live media content and an overlay, the overlay comprising the supplementary content.
|