| CPC G06F 16/7343 (2019.01) [G06F 16/783 (2019.01); G06N 3/04 (2013.01); G06V 20/40 (2022.01)] | 20 Claims |
|
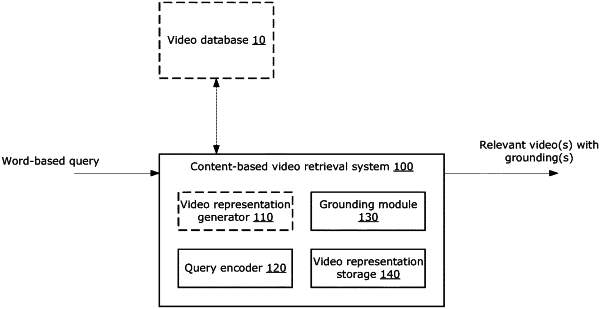
1. A method comprising:
receiving a word-based query for a video;
encoding the word-based query into a query representation using a trained query encoder;
performing a video retrieval task by identifying, from among a plurality of video representations each representing a respective untrimmed video, one or more similar video representations that are similar to the query representation, each similar video representation representing a respective relevant video;
performing a video grounding task by generating a grounding for each relevant video by forward propagating each respective similar video representation together with the query representation through a trained grounding module, each respective similar video representation being used for both the video retrieval task and the video grounding task; and
outputting one or more identifiers of the one or more relevant videos together with the grounding generated for each relevant video;
wherein each of the plurality of video representations is generated using a trained video representation generator; and
wherein the video representation generator is trained together with the query encoder using a training dataset of videos having ground-truth multi-sentence annotations, the query encoder being trained to generate a query representation from a given sentence in a given annotation that matches a high-level sentence representation generated by a text-processing branch of the video representation generator from the given sentence and the query representation generated from the given sentence in the given annotation aligns with a high-level clip representation generated by a video-processing branch of the video representation generator from a clip corresponding to the given sentence.
|