| CPC H04L 63/1466 (2013.01) [G06F 17/18 (2013.01); G06N 3/045 (2023.01); G06N 3/084 (2013.01); G06N 20/10 (2019.01); G10L 17/00 (2013.01); G10L 17/04 (2013.01); G10L 17/26 (2013.01); G10L 19/26 (2013.01); H04L 65/75 (2022.05)] | 22 Claims |
|
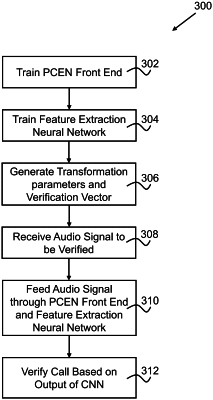
1. A computer-implemented method for implementing an anti-spoofing end-to-end neural network architecture, the method comprising:
receiving, by a computer, a raw audio signal of a call purportedly associated with a verified speaker identity;
generating, by the computer executing a convolution layer of a signal processing frontend of a neural network architecture, a two-dimensional transformed representation from the received raw audio signal based upon a set of bandpass filter parameters, thereby resulting in a processed audio signal;
filtering, by the computer executing the signal processing frontend of the neural network architecture, the processed audio signal into frequency channels by applying a filterbank; and
generating, by the computer executing the neural network architecture, a prediction score for the processed audio signal, the prediction score indicating a likelihood the processed audio signal of the call is associated with a spoof of the verified speaker identity;
wherein the neural network architecture is trained according to a plurality of raw audio signals having at least one raw audio signal for at least one verified call associated with the verified speaker identity and at least one raw audio signal for at least one spoofed call.
|