| CPC G10L 15/22 (2013.01) [G10L 15/065 (2013.01); G10L 15/10 (2013.01); G10L 15/30 (2013.01)] | 20 Claims |
|
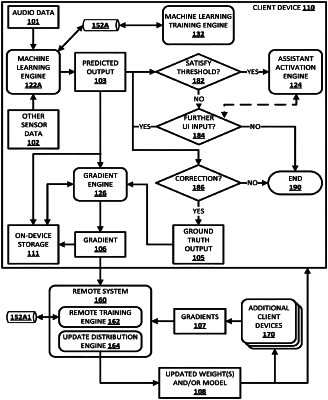
20. A client device comprising:
one or more hardware processors; and
memory storing instructions that, when executed by the one or more hardware processors, cause the one or more hardware processors to:
receive, via one or more microphones of the client device, audio data that captures a spoken utterance of a user;
process the audio data using a machine learning model, stored locally at the client device, to generate a predicted output;
make a decision, based on the predicted output failing to satisfy a threshold, to refrain from initiating one or more currently dormant automated assistant functions;
subsequent to making the decision to refrain from initiating the one or more currently dormant automated assistant functions:
receive, via the client device, further user interface input to initiate one or more of the currently dormant automated assistant functions and that contradicts the decision to refrain from initiating one or more of the currently dormant automated assistant functions; and
determine, based on a duration of time between receiving the audio data that was processed in making the decision and receiving the further user interface input that contradicts the decision, that the decision to refrain from initiating one or more of the one or more currently dormant automated assistant functions was incorrect; and
in response to determining that the decision was incorrect:
generate a gradient based on comparing the predicted output to ground truth output that satisfies the threshold, and
transmit, over a network and to a remote system, the generated gradient without transmitting any of: the audio data and the further user interface input,
wherein the remote system utilizes the generated gradient, and additional gradients from additional client devices, to update global weights of a global machine learning model that is a global counterpart of the machine learning model that is stored locally at the client device.
|