| CPC G10L 15/063 (2013.01) [G10L 15/187 (2013.01); G10L 15/22 (2013.01); G10L 15/30 (2013.01); G10L 2015/0635 (2013.01)] | 20 Claims |
|
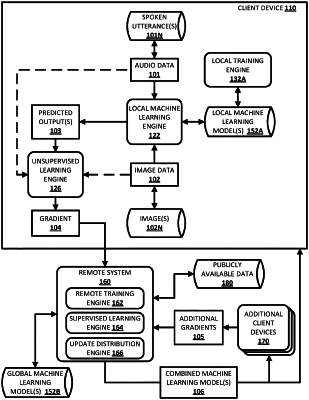
1. A method performed by one or more processors of a client device, the method comprising:
detecting, via one or more microphones of the client device, audio data that captures at least part of a spoken utterance of a user of the client device;
processing, using a local machine learning model stored locally on the client device, the audio data to generate predicted output,
wherein the local machine learning model includes at least a first set of local machine learning model layers and a second set of machine learning model layers,
wherein the first set of local machine learning model layers is used in generating, based on processing the audio data, an encoding of the audio data, and
wherein the second set of local machine learning model layers is used in generating, based on processing the encoding of the audio data that is generated using the first set of local machine learning model layers, the predicted output;
generating, using unsupervised learning, a gradient based on the predicted output; and
transmitting, to a remote system and from the client device, the generated gradient to cause the remote system to utilize the generated gradient to update weights of global machine learning model layers that are stored remotely at the remote system and that correspond structurally to the first set of local machine learning model layers, of the local machine learning model, used in generating the encoding of the audio data, and
subsequent to the remote system updating the weights of the global machine learning model layers utilizing the generated gradient received from the client device and additional gradients received from additional client devices:
receiving, at the client device and from the remote system, a combined machine learning model that includes the updated global machine learning model layers and one or more additional layers; and
using the combined machine learning model to make at least one prediction based on further audio data, detected via one or more of the microphones of the client device, that captures at least part of a further spoken utterance of the user of the client device.
|