| CPC G06V 20/49 (2022.01) [G06F 18/231 (2023.01); G06V 20/41 (2022.01); G06V 20/46 (2022.01); G10L 25/78 (2013.01); G11B 27/002 (2013.01); G11B 27/19 (2013.01); G06V 20/44 (2022.01)] | 20 Claims |
|
1. A method comprising:
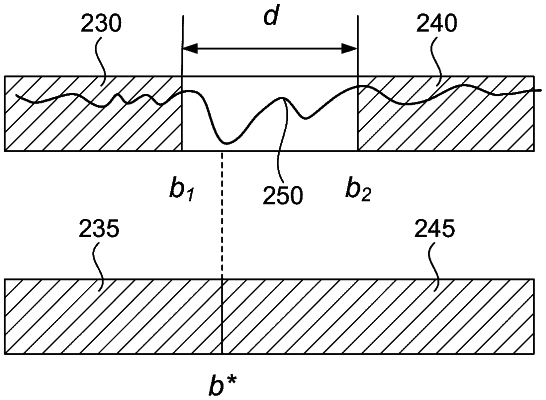
generating a representation of a hierarchical segmentation of a video timeline of a video based on adjusting locations of detected speech boundaries using voice-activity detection (VAD) scores of audio of the video to close a non-speech segment between two speech segments; and
providing at least one level of the hierarchical segmentation of the video timeline for presentation.
|