| CPC G06T 17/20 (2013.01) [G06T 7/73 (2017.01); G06T 7/80 (2017.01); G06T 7/90 (2017.01); G06T 19/006 (2013.01); G06T 2200/08 (2013.01); G06T 2207/10016 (2013.01); G06T 2207/10024 (2013.01); G06T 2207/20084 (2013.01); G06T 2207/30201 (2013.01)] | 6 Claims |
|
1. A data acquisition and reconstruction method for human body three-dimensional modeling based on a single mobile phone, comprising:
step S1, data acquisition based on augmented reality technology, comprising:
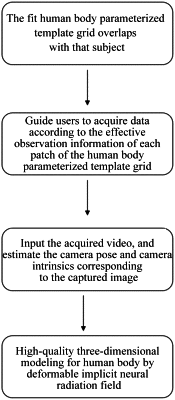
step S1.1, a subject standing in a scene, keeping a posture with spread human body surface conducive to reconstruction, a user capturing 360° view on the subject via a mobile phone, fitting a human parametric template mesh according to a body shape and a posture of the subject from multiple view angles, and rendering the human parametric template mesh in a scene position where the subject stands by augmented reality technology, so as to approach a visual effect that the human parametric template mesh and the subject are overlapped; and
step S1.2, during the data acquisition, guiding the user for a data acquisition process by using the fitted human parametric template mesh, determining whether a single face on the human parametric template mesh at a current perspective is effectively observed, wherein when a face meets both the distance standard and the line-of-sight angle standard for effective observation at a certain perspective, an effective observation count of the face being increased by one; and
wherein when the effective observation count of the face reaches a set number threshold, the face has an enough number of observations, the color mark of the face is changed, and the user is indicated that acquisition at a position of the face has been completed; the camera is moved to acquire data in areas that have not been observed enough; when all faces on the human parametric template grid change in color, the data acquisition process is completed;
step S2, reconstruction of a three-dimensional human model based on a deformable implicit neural radiance field, comprising:
step S2.1, extracting a video acquired in S1.2 into a series of image sequences captured around a human body, and estimating a camera pose and camera intrinsics corresponding to captured images according to a matching relationship of feature points among the images; and
step S2.2, modelling a human body in three dimensions using the deformable implicit neural radiance field, wherein the deformable implicit neural radiance field comprises an implicit spatial deformation field estimation model, an implicit signed distance field estimation model and an implicit color estimation model;
establishing the implicit spatial deformation field estimation model from an observation frame coordinate system corresponding to each image frame to a canonical space using a neural network, wherein an input of the implicit spatial deformation field estimation model is a coordinate of a three-dimensional point in the observation frame coordinate system, and an output of the implicit spatial deformation field estimation model is a coordinate of the three-dimensional point in a canonical coordinate system;
establishing the implicit signed distance field estimation model for expressing a canonical shape in the canonical space using the neural network, wherein an input of the implicit signed distance field estimation model is a coordinate of the three-dimensional point in the canonical space, and an output of the implicit signed distance field estimation model is a signed distance and geometric characteristics of the three-dimensional point;
establishing the implicit color estimation model for observing colors of the three-dimensional point from a specific direction in the canonical space using the neural network, wherein an input of the implicit color estimation model is geometric characteristics of the three-dimensional point and a vector representing a line of sight output by the implicit signed distance field estimation model, and an output is a color of each sampling point along a specific line of sight estimated by the model;
optimizing the implicit spatial deformation field estimation model, the implicit signed distance field estimation model and the implicit color estimation model based on the camera pose and the camera intrinsics corresponding to the images obtained in S2.1 by volume rendering on an input image set to obtain an implicit three-dimensional human body model; and
post-processing an implicit signed distance field of the deformable implicit neural radiance field by an isosurface extraction method to obtain an explicit three-dimensional human model.
|