| CPC G06T 13/40 (2013.01) [G06V 10/7747 (2022.01); G06V 40/174 (2022.01)] | 19 Claims |
|
1. A method for generating an avatar, comprising:
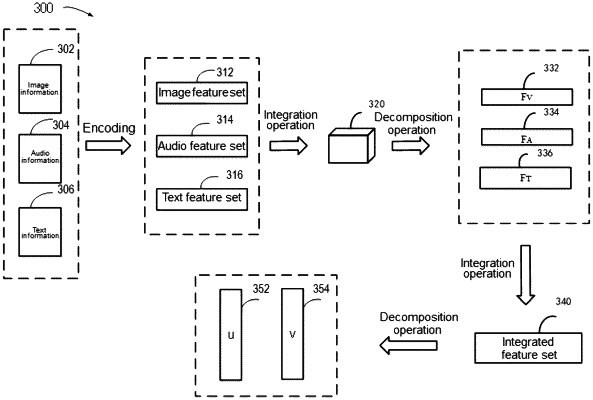
generating an indication of correlation among image information, audio information, and text information of a video, the indication of the correlation comprising a tensor characterizing feature element associations between corresponding feature elements of the image information, the audio information, and the text information;
generating, based on the indication of the correlation and at least in part through application of a decomposition process to the tensor, a first feature set and a second feature set representing features of a target object in the video, wherein the first feature set represents invariant features of the target object in the video, and the second feature set represents equivariant features of the target object in the video; and
generating the avatar based on the first feature set and the second feature set;
wherein generating, based on the indication of the correlation, a first feature set and a second feature set representing features of a target object in the video comprises:
decomposing the tensor to obtain a decomposed image feature set, a decomposed audio feature set, and a decomposed text feature set; and
integrating the decomposed image feature set, the decomposed audio feature set, and the decomposed text feature set to generate an integrated feature set; and
wherein generating, based on the indication, a first feature set and a second feature set representing features of a target object in the video further comprises:
decomposing the integrated feature set into the first feature set and the second feature set.
|