| CPC G06N 3/126 (2013.01) [G16H 10/20 (2018.01); G16H 10/40 (2018.01); G16H 15/00 (2018.01); G16H 50/70 (2018.01); G16H 70/60 (2018.01)] | 20 Claims |
|
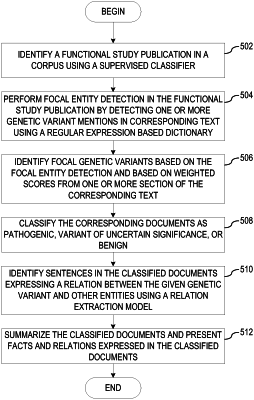
1. A method, in a data processing system, for processing electronic documents to identify genetic variants of a gene, the method comprising:
executing a first computer-implemented machine learning training of a first machine learning computer model based on a first labeled training dataset to train the first machine learning computer model to detect genetic variant mentions in natural language text of first electronic documents using a regular expression dictionary and focal genetic variant identification, to thereby generate a first trained machine learning computer model;
executing a second computer-implemented machine learning training of a second machine learning computer model based on a second labeled training dataset to train the second machine learning computer model to extract relations between genetic variants and other entities from the natural language text of the first electronic documents based on a knowledge bank of known relations between entities, to thereby generate a second trained machine learning computer model;
extracting evidence of one or more genetic variants of the gene and corresponding information from second electronic documents in a corpus of information, at least by executing the first trained machine learning computer model and the second trained machine learning computer model on the second electronic documents, wherein the evidence comprises genetic variant mentions and genetic variant relations for corresponding ones of the one or more genetic variants;
classifying each genetic variant of the one or more genetic variants based on whether the genetic variant is identified as being pathogenic in the evidence of the one or more genetic variants at least by executing an algorithm that predicts whether the genetic variant is within a predetermined distance of a splicing site; and
performing genetic variant annotation to generate a summary at least by extracting portions of the plurality of documents corresponding to the genetic variant mentions of the one or more genetic variants and genetic variant relations and executing natural language processing on the identified portions to generate the summary.
|