| CPC G06N 3/082 (2013.01) [G06N 3/045 (2023.01)] | 6 Claims |
|
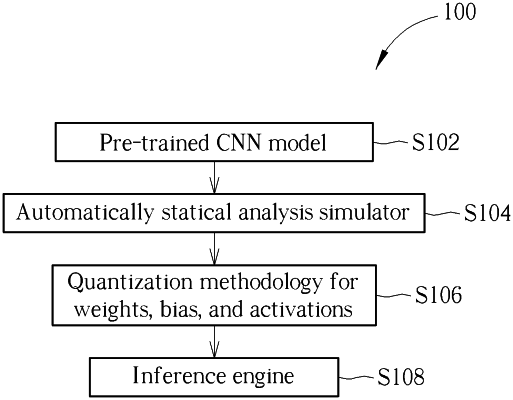
1. A method of quantizing a floating pre-trained convolution neural network (CNN) model comprising:
inputting input data to the floating pre-trained CNN model to generate floating feature maps for each layer of the floating pre-trained CNN model;
inputting the floating feature maps to a statistical analysis simulator to generate a dynamic quantization range for each layer of the floating pre-trained CNN model; and
quantizing the floating pre-trained CNN model according to the dynamic quantization range for each layer of the floating pre-trained CNN model to generate a quantized CNN model, a scalar factor of each layer of the floating pre-trained CNN model, and a fractional bit-width of the quantized CNN model, wherein quantizing the floating pre-trained CNN model comprises:
acquiring a plurality of weights of each layer of the floating pre-trained CNN model;
setting the scalar factor of each layer of the floating pre-trained CNN model according to a maximum weight of the plurality of weights and a minimum weight of the plurality of weights;
applying the scalar factor of each layer of the floating pre-trained CNN model to an activation vector at each layer of the floating pre-trained CNN model; and
minimizing a quantization error of each layer of the quantized CNN model according to the scalar factor by using a minimum mean square error approach as
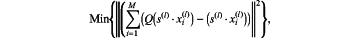 wherein s(l) is the scalar factor at an l-th layer, xi(l) represents output features in an i-th channel at the l-th layer, Q( ) is a quantization function, and M is a total number of channels;
wherein the scalar factor of each layer of the floating pre-trained CNN model is associated with a quantization bit-width and the dynamic quantization range when quantizing the floating pre-trained CNN model.
|