| CPC G06N 20/00 (2019.01) [G06F 9/54 (2013.01); G06F 30/27 (2020.01); G06N 5/04 (2013.01); H04L 41/16 (2013.01)] | 19 Claims |
|
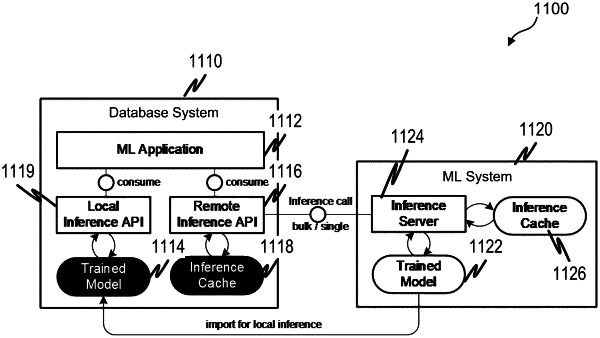
1. A method for reducing resource consumption of a database and a machine learning (ML) system, the method implemented by one or more data processors forming part of at least one computing device and comprising:
receiving, during an inference time of the ML system, from a ML application of a database, data comprising a first inference call for a predicted response to the received data, wherein the first inference call is a request to a ML model to generate one or more predictions for which a response is unknown, the database including logic for accessing data stored in the database and being an in-memory database in which all data stored in the in-memory database is kept in main memory separate and distinct from any processor;
generating, by the ML model using the received data, an output comprising the predicted response to the data;
caching, in an inference cache, the output for future inference calls so as to bypass the ML model;
providing, by the ML model, the generated output to the ML application;
receiving a second inference call comprising the data of the first inference call; and
retrieving, from the inference cache, the cached output, wherein the retrieving bypasses the ML model.
|