| CPC G06F 8/33 (2013.01) | 20 Claims |
|
1. A system comprising:
at least one processor; and
a memory storing program instructions that, when executed by the at least one processor, cause the at least one processor to implement a code generation system, the code generation system configured to:
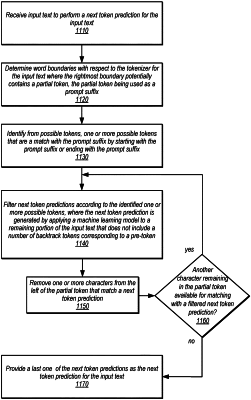
receive input programming code to perform a next token prediction for the input programming code;
determine word boundaries with respect to a tokenizer for the input programming code where rightmost boundary contains a partial token, the partial token being used as a prompt suffix;
identify, from a plurality of tokens, one or more tokens that are a match with the prompt suffix and that start with the prompt suffix or end with the prompt suffix;
filter next token predictions according to the one or more tokens, wherein the next token predictions are generated by applying a machine learning model, trained to predict next tokens for a programming code, to a remaining portion of the input programming code that does not include a number of backtrack tokens corresponding to a pre-token, wherein the filtering is performed for one or more iterations to remove, after each iteration, one or more characters from left side of the partial token until there are no remaining characters in the partial token, wherein the one or more characters match one of the next token predictions; and
provide a last one of the next token predictions as the next token prediction for the input programming code.
|