| CPC B60W 60/001 (2020.02) [B60W 30/0956 (2013.01); G06F 18/214 (2023.01); G06N 20/00 (2019.01); G06V 10/774 (2022.01); G06V 10/7788 (2022.01); G06V 20/46 (2022.01); G06V 20/48 (2022.01); G06V 20/58 (2022.01); G06V 40/20 (2022.01); B60W 2420/403 (2013.01)] | 20 Claims |
|
1. A method comprising:
receiving a sequence of video frames captured by a camera mounted on an autonomous vehicle;
sampling the sequence of video frames to obtain a subset of video frames;
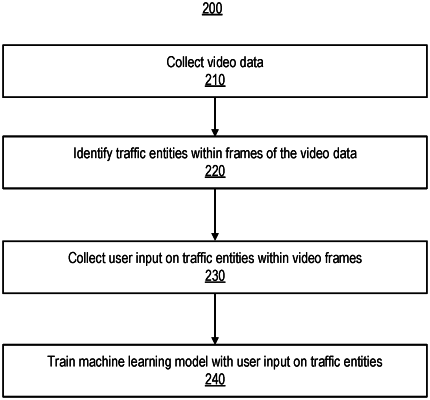
annotating each of the subset of video frames obtained by sampling, each annotation specifying an attribute value describing a statistical distribution of user responses obtained by presenting the video frame to a plurality of users, each user response representing a likelihood of a state of mind represented by a hidden context for a traffic entity displayed in the video frame;
identifying a pair of video frames from the subset of video frames, the pair of video frames comprising a first video frame and a second video frame, wherein a time of capture of the first video frame and a time of capture of the second video frame is separated by a first time interval;
comparing a first attribute value associated with the first video frame and a second attribute value associated with the second video frame;
responsive to the first attribute value being within a threshold of the second attribute value, annotating a third video frame from the sequence of video frames having a time of capture within the first time interval by interpolating using the first attribute value and the second attribute value;
providing a training data set including the annotated subset of video frames and the third video frame for training a machine learning model, the machine learning model configured to receive an input video frame displaying a traffic entity and predict a statistical distribution of user responses representing the likelihood of the state of mind of the traffic entity displayed in the input video frame; and
providing the trained machine learning model to the autonomous vehicle to assist with navigation in traffic.
|