| CPC H04R 3/005 (2013.01) [H04R 5/04 (2013.01)] | 20 Claims |
|
14. An electronic device comprising:
at least one processor; and
memory having instructions stored therein which when executed by the at least one processor causes the electronic device to:
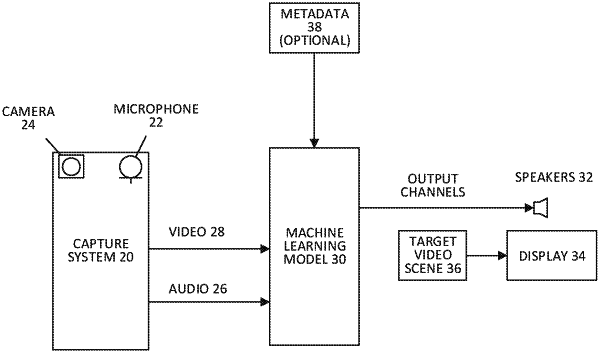
receive input audio data that includes a sound, video data, and metadata comprising a target scene that includes a visual representation of the sound; and
generate output audio data in a target output audio format as output of a machine learning (ML) model using 1) the input audio data, 2) the video data, and 3) the target scene as input, wherein the ML model maps the input audio data to the output audio data according to the target output audio format, wherein the output audio data comprises the sound that is spatially mapped according to a location of the visual representation within the target scene, wherein the ML model outputs the output audio data based on one or more correlations between the sound and visual information of the video data.
|