| CPC G06V 20/46 (2022.01) [G06F 16/785 (2019.01); G06N 20/00 (2019.01); G06T 5/70 (2024.01); G06V 10/70 (2022.01); G06V 20/70 (2022.01)] | 20 Claims |
|
1. A method, comprising:
receiving a set of video frames corresponding to a video;
determining a first subset of video frames by removing, from the set of video frames, those video frames which are outside of an image quality threshold;
determining a second subset of video frames by removing, from the first subset of video frames, those video frames which are outside of an image stillness threshold;
computing feature data for each video frame in the second subset of video frames;
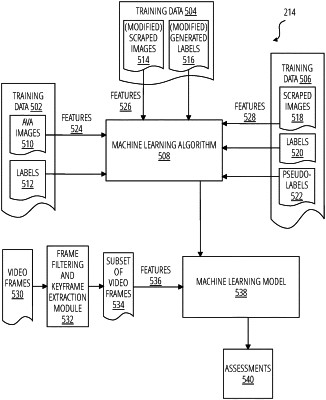
providing, for each video frame in the second subset of video frames, the feature data of the video frame as input to a machine learning model,
wherein the machine learning model is configured to output a score for each video frame in the second subset of video frames based on the feature data of the video frame, the machine learning model having been trained with a first set of images labeled based on image aesthetics, and further having been trained with second set of images labeled based on image quality, the first and second set of images being associated with different domains; and
selecting, from among the second subset of video frames, a video frame to represent the set of video frames based on the scores output by the machine learning model.
|