| CPC G06V 10/255 (2022.01) [G06F 18/214 (2023.01); G06N 3/08 (2013.01); G06T 7/246 (2017.01); G06T 7/292 (2017.01); G06T 7/80 (2017.01); G06V 20/10 (2022.01); G06V 20/52 (2022.01)] | 20 Claims |
|
1. A system, comprising:
a storage device storing a set of instructions; and
at least one processor configured to communicate with the storage device, wherein when executing the set of instructions, the at least one processor is directed to cause the system to perform operations including:
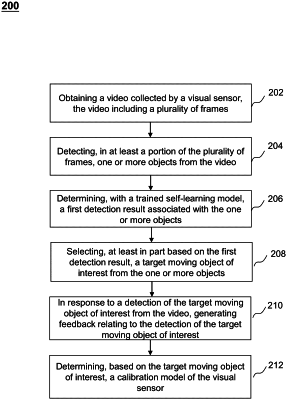
obtaining a video collected by a visual sensor, the video including a plurality of frames;
detecting, in at least a portion of the plurality of frames, one or more objects from the video;
determining, with a trained self-learning model, a first detection result associated with the one or more objects;
determining, based on the at least a portion of the plurality of frames, one or more behavior features associated with each of the one or more objects;
determining, based on the one or more behavior features associated with each of the one or more objects, a second detection result associated with each of the one or more objects; and
determining, based on the first detection result and the second detection result, a tartlet moving object of interest from the one or more objects, wherein the trained self-learning model is provided based on a plurality of training samples collected by the visual sensor.
|