| CPC G06T 3/4046 (2013.01) [G06T 9/002 (2013.01)] | 28 Claims |
|
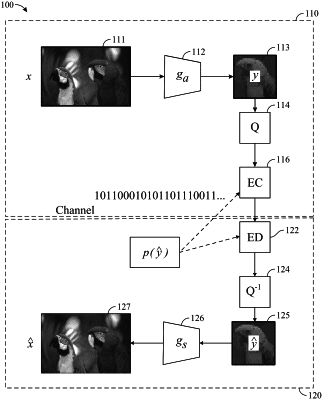
1. A method for compressing content using a neural network, comprising:
receiving content for compression;
encoding the content into a first latent code space through an encoder implemented by an artificial neural network;
generating a first compressed version of the encoded content using a first quantization bin size of a series of quantization bin sizes;
generating a refined compressed version of the encoded content by scaling the first compressed version of the encoded content into one or more second quantization bin sizes in the series of quantization bin sizes smaller than the first quantization bin size, conditioned at least on a value of the first compressed version of the encoded content; and
outputting the refined compressed version of the encoded content;
wherein generating the refined compressed version of the encoded content comprises:
generating a first refined compressed version of the encoded content by scaling the first compressed version of the encoded content into a first finer quantization bin size, conditioned on a value of the first compressed version of the encoded content; and
generating a second refined compressed version of the encoded content by scaling the first refined compressed version of the encoded content into a second finer quantization bin size conditioned on a value of the first refined compressed version of the encoded content and the first compressed version of the encoded content, wherein the second finer quantization bin size is smaller than the first finer quantization bin size.
|