| CPC G06N 3/08 (2013.01) [G06N 3/04 (2013.01); G06N 3/063 (2013.01)] | 12 Claims |
|
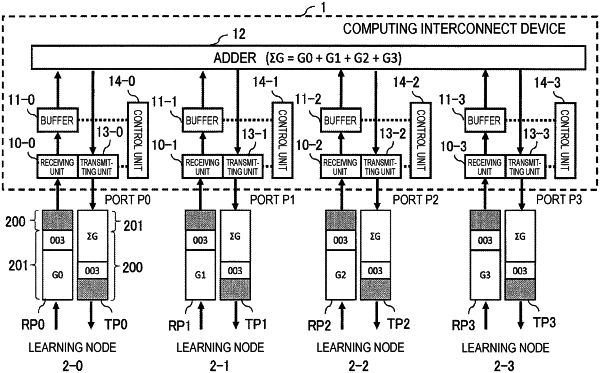
1. A distributed deep learning system comprising:
a plurality of learning nodes; and
a plurality of computing interconnect device connected to the plurality of learning nodes via a communication network;
wherein each learning node of the plurality of learning nodes comprises:
one or more first processors; and
a first non-transitory computer-readable storage medium storing a first program to be executed by the one or more first processors, the first program including instructions to:
calculate a gradient of a loss function from an output result obtained by inputting learning data to a learning target neural network corresponding to the learning node;
convert the gradient of the loss function into a first packet;
transmit the first packet to a computing interconnect device of the plurality of computing interconnect devices;
acquire a value stored in a second packet received from the computing interconnect device; and
update a constituent parameter of the learning target neural network based on the value stored in the second packet; and
wherein a first computing interconnect device of the plurality of computing interconnect devices that is positioned at highest order among the plurality of computing interconnect devices comprises:
one or more second processors; and
a second non-transitory computer-readable storage medium storing a second program to be executed by the one or more second processors, the second program including instructions to:
receive a third packet from a second computing interconnect device of the plurality of computing interconnect devices, the second computing interconnect device is at an immediately lower order than the first computing interconnect device;
receive a fourth packet transmitted from a first learning node of the plurality of learning nodes that is connected to the first interconnect computing device;
acquire a value of a gradient stored in the third packet and a value of a gradient stored in the fourth packet;
perform calculation processing on the value of the gradient in the third packet and the value of the gradient in the fourth packet;
convert a calculation result of the calculation processing into a fifth packet; and
transmit the fifth packet to the second computing interconnect device at the immediately lower order than the first computing interconnect device and to the first learning node connected to the first computing interconnect device.
|